H‰ufigkeitsanalyse

Um einen durch Caesar-Verschiebung verschl¸sselten Text zu knacken,
war es viel zu m¸hsam und zeitaufw‰ndig, alle Schl¸ssel auszuprobieren.
Wie also konnte man eine verschl¸sselte Botschaft schneller knacken?
Im 9. Jahrhundert ist dem arabischen Gelehrten al-Kindi (Orient) zum ersten
Mal die unterschiedliche H‰ufigkeitvon Buchstaben in einer nat¸rlichen Sprache
bewusst geworden; was eine Mˆglichkeit der Entschl¸sselung darbot.
Nat¸rliche Sprachen haben relativ wenige Buchstaben, die sehr unterschiedliche
H‰ufigkeiten aufweisen.
Hier einige Beispiele:
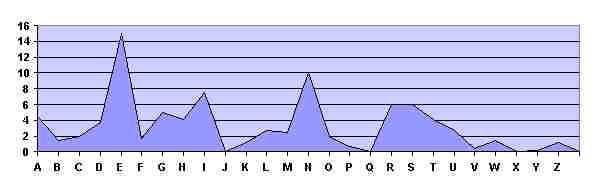
1. deutsche Sprache:
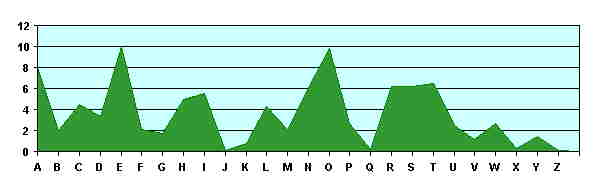
2. englische Sprache:
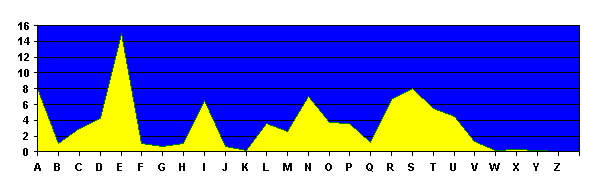
3. franzˆsische Sprache:
Um diese Buchstabenverteilung herauszufinden, haben wir das
Programm
verwendet.
Sie kˆnnen es gerne selber einmal ausprobieren. Klicken Sie dazu bitte auf
das unterstrichene Wort.
Wir wollen das weitere Vorgehen der Sprachwissenschaftler und Statistiker
an der deutschen Sprache veranschaulichen.
Anhand Abb1.1 erkennt man sofort eine charakteristische Verteilung der Buchstaben
in der deutschen Sprache:
- Die e-Spitze und der n-Gipfel
- Der b-c-d-Anstieg mit anschlieþender e-Spitze
Diese Struktur findet man auch in jedem monoalphabetisch verschl¸sselten deutschen
Text (mittels Caesarverschiebung).
Die 5 h‰ufigsten Buchstaben e-n-i-s-r decken bereits 50 % der vorkommenden
Buchstaben ab, die h‰ufigsten 10 dann ¸ber 75 %.
Zuerst ermittelt der Kryptoanalytiker nun die H‰ufigkeitsverteilung der Buchstaben
im abgefangenen Geheimtext, den er eventuell als Stabdiagramm darstellt.
So erkennt er wenigstens die beiden h‰ufigsten Buchstaben, denn bei der
Caesar-Verschl¸sselung wird sich eine ‰hnliche Verteilunsfunktion ergeben,
nur verschoben.
Im zweiten Schritt schaut er sich die Buchstaben paarweise an.
Das Bigramm der deutschen Sprache zeigt die h‰ufigsten Kombinationen.
| Bigramm |
Buchstabenpaar |
Rel.H‰ufigkeit |
| 1 |
en |
0.0388 |
| 2 |
er |
0.0375 |
| 3 |
ch |
0.0275 |
| 4 |
te |
0.026 |
| 5 |
de |
0.02 |
| 6 |
nd |
0.0199 |
| 7 |
ei |
0.0188 |
| 8 |
ie |
0.0179 |
| 9 |
in |
0.0167 |
| 10 |
es |
0.0152 |
Damit man einen Text ¸berhaupt entschl¸sseln kann, muss er eine gewisse
L‰nge haben, da es sonst schwierig ist, die H‰ufigkeitsanalyse durchzuf¸hren.
Wir mˆchten dieses Vorgehen der Kryptoanalytiker nun an einem Beispiel verdeutlichen.
Hierzu verwenden wir einen Teil des monoalphabetisch verschl¸sselten Text der
Caesar-Verschl¸sselung
, der ¸ber diesen hinaus geht.
"JXQCHLQIDFK: PDQVLHKWQXUPLWGHPKHUCHQJXW.
GDVZHVHQWOLFKHLVWIXHUGLHDXJHQXQVLFKWEU.
'GDVZHVHQWOFKHLVWIXHUGLHDXJHKXQVLFFKWEU',
ZLHGHUKROWHGHUNOHLQHSULQC,XJHVVLFKCXPHUNHQ.
'GLHCHFW;GLHGXIXHUGHXQHURVHYHUORUHQKDVW,
VLHPDFKWGHLQHURVHVRZLFKWLJ.'
'GLHCHLW;GLHLFKIXHUPHLQHURVHYHUORUHQKDEH ...',
VDJWHGHUNOHLQHSULQC,XJHVVLFKCXPHUNHQ.
'GlEPHQFKHQKDEQGLHVHZDKUKHLWYHUJHVVHQ',
VDJWHGHUIXFKS."
1. Bestimmung der relativen H‰ufigkeit der Buchstaben mittels des
Programms
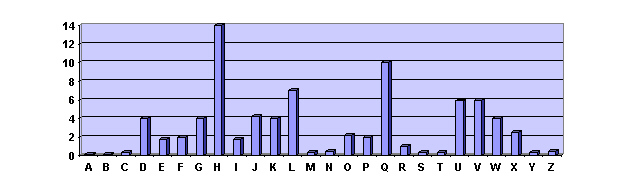
2. Aufstellen eines Stabdiagramms
3. Aufstellen eines Bigramms
Da der Buchstabe 'h' am h‰ufigsten im Geheimtext vorkommt, kann es eigentlich
nur das 'e' sein.
Der zweith‰ufigste Buchstabe ist das 'q'. Er kommt in der Kombination 'qh' als
h‰ufigstes Bigramm vor. Folglich ist 'q' eindeutig das 'n'.
Es gibt nur zwei Bigramme der deutschen Sprache mit ebendieser H‰ufigkeit, in
denen der zweite Buchstabe ein n ist: en und in.
Damit ist auch das 'i' ent
schl¸sselt, es war ein 'l'.
Das zweith‰ufigste Bigramm der deutschen Sprache ist 'er'. Das 'e' haben wir identifiziert,
es heiþt jetzt 'h'.
Das Paar 'hu' - das einzige, das mit 'h' beginnt und
noch nicht identifiziert ist - kommt in Frage, einmal das gesuchte 'er' gesesen zu sein.
Das 'u' kommt mit einer relativen H‰ufigkeit von 5,9 % im Geheimtext vor, das 'r' hat
in der deutschen Sprache die H‰ufigkeit 6 %, das scheint zu passen.
Wenn wir die Buchstaben aus der R¸ckersetzung einsetzen (mittels eines Programms),
so entsteht ein L¸ckentext, der aufgef¸llt werden muss.
Man kann einzelne Wˆrter erkennen, z.B. PHLQH. _eine kann nur 'deine',
'meine' oder 'seine' heiþen.
Durch Probieren findet man relativ schnell
die Lˆsung des verschl¸sselten Textes.
Das einzigen Problem dabei ist, dass die Worte einfach hintereinander geschrieben
sind, was die Bigrammanalyse verzerrt.
Zusammenfassend kann man sagen, dass die Kryptoanalytiker die unterschiedlichen
H‰ufigkeiten der Buchstaben in nat¸rlichen Sprachen ausgenutzt haben, um momoalpabetisch
verschl¸sselte Texte zu knacken.
Man hat mittlerweile viele neue Verfahren gefunden, um Texte zu verschl¸sseln.
Einige davon finden Sie auf den Seiten zur
Kryptologie.